
The joint error covariance matrix of observed and predicted data for Kalman Filtering (KF) of a typical geophysical problem is immense but sparse. The total computing load of an exact numerical inversion is proportional to the cubic of size N of this N*N square symmetric matrix. Prof. Dr. Tzvi Gal-Chen (1941-1994), the late Professor of Meteorology in the University of Oklahoma (OU), identified this immense magnitude of a reliable Kalman solution and ended up with proposing parallel supercomputing, see Bull. Am. Met. Soc., Vol. 71, No. 5, May 1990, page 684.
It has turned out that the sparsity of the error covariance matrix can be exploited analytically as first outlined by Prof. F. R. Helmert already in 1880 and later by Lange in 1987. This often makes an exact solution of all the parameters to be estimated up to N times faster to compute. The patented Fast Kalman Filtering (FKF, 1990, 1993, and 1996) exploits the Helmert-Wolf blocking (HWB, 1978) method by taking the following steps:
The suggested parallel computing and the patented FKF computations are complementary. Stability of the FKF filtering is crucial for safety of many sophisticated services that will increasingly rely on automation. Estimating various time-varying model and calibration parameters (including the Canonical Common Variates) of any large system calls for their sufficient observability. Continuously inflowing observed and predicted data can then be rapidly analysed in large moving batches for an improved observability. Fortunately, the blockwise computing of FKF speeds up Kalman filtering the more drastically the more data are to be processed at a time. Thus, supercomputing may not always be needed for the Statistical Calibration and Model Identification of Adaptive Kalman Filtering (AKF). In fact, light-weight position-finding (LiteFix) devices are foreseen to be based on FKF for use in most secure operations of safety-critical services.
* Last revised: June 11, 2004{kind=link}
{kind=link}
{kind=link}
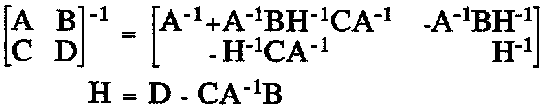{kind=link}